汇编语言
3.3 X86 汇编基础
3.3.2 寄存器 Registers
现代 ( 386及以上的机器 )x86 处理器有 8 个 32 位通用寄存器, 如图 1 所示.
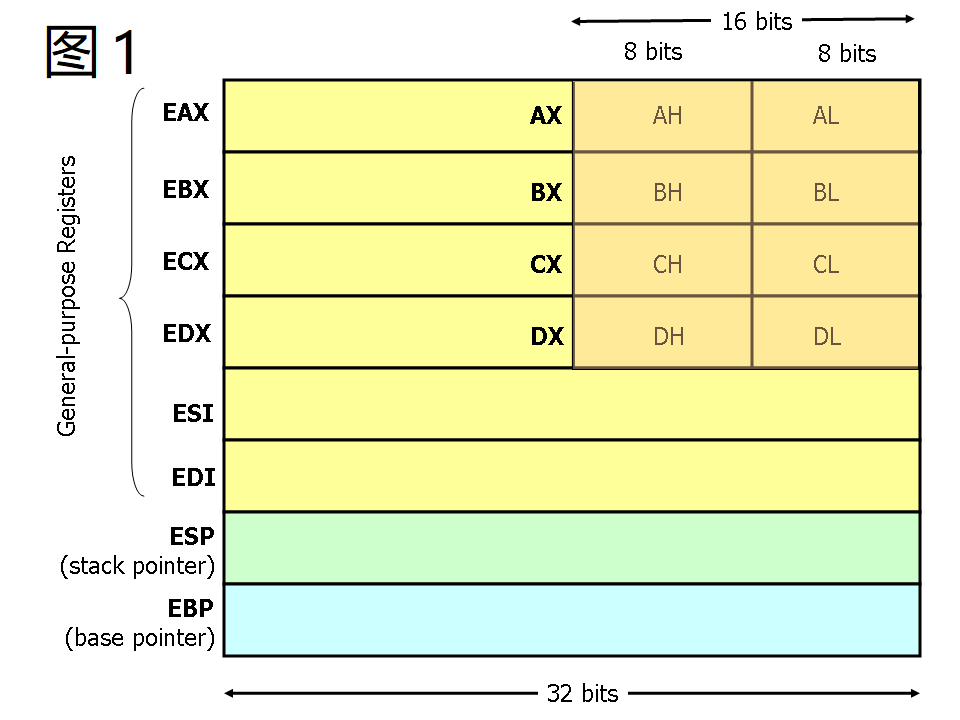
这些寄存器的名字都是有点历史的, 例如 EAX 过去被称为 累加器, 因为它被用来作很多算术运算, 还有 ECX 被称为 计数器 , 因为它被用来保存循环的索引 ( 就是循环次数 ). 尽管大多是寄存器在现代指令集中已经失去了它们的特殊用途, 但是按照惯例, 其中有两个寄存器还是有它们的特殊用途 ---ESP 和 EBP.
对于 EAS, EBX, ECX 还有 EDX 寄存器, 它们可以被分段开来使用. 例如, 可以将 EAX 的最低的 2 位字节视为 16 位寄存器 ( AX ). 还可以将 AX 的最低位的 1 个字节看成 8 位寄存器来用 ( AL ), 当然 AX 的高位的 1 个字节也可以看成是一个 8 位寄存器 ( AH ). 这些名称有它们相对应的物理寄存器. 当两个字节大小的数据被放到 DX 的时候, 原本 DH, DL 和 EDX 的数据会受到影响 ( 被覆盖之类的 ). 这些 " 子寄存器 " 主要来自于比较久远的 16 位版本指令集. 然而, 姜还是老的辣, 在处理小于 32 位的数据的时候, 比如 1 个字节的 ASCII 字符, 它们有时会很方便.
3.3.3 内存和寻址模式 Memory and Addressing Modes
3.3.3.1 声明静态数据区域
你可以用特殊的 x86 汇编指令在内存中声明静态数据区域 ( 类似于全局变量 ). .data指令用来声明数据. 根据这条指令, .byte, .short 和 .long 可以分别用来声明 1 个字节, 2 个字节和 4 个字节的数据. 我们可以给它们打个标签, 用来引用创建的数据的地址. 标签在汇编语言中是非常有用的, 它们给内存地址命名, 然后编译器 和链接器 将其 " 翻译 " 成计算机理解的机器代码. 这个跟用名称来声明变量很类似, 但是它遵守一些较低级别的规则. 例如, 按顺序声明的位置将彼此相邻地存储在内存中. 这话也许有点绕, 就是按照顺序打的标签, 这些标签对应的数据也会按照顺序被放到内存中.
一些例子 :
.data
var :
.byte 64 ;声明一个字节型变量 var, 其所对应的数据是64
.byte 10 ;声明一个数据 10, 这个数据没有所谓的 " 标签 ", 它的内存地址就是 var+1.
x :
.short 42 ;声明一个大小为 2 个字节的数据, 这个数据有个标签 " x "
y :
.long 30000 ;声明一个大小为 4 个字节的数据, 这个数据标签是 " y ", y 的值被初始化为 30000
与高级语言不同, 高级语言的数组可以具有多个维度并且可以通过索引来访问, x86 汇编语言的数组只是在内存中连续的" 单元格 ". 你只需要把数值列出来就可以声明一个数组, 比如下面的第一个例子. 对于一些字节型数组的特殊情况, 我们可以使用字符串. 如果要在大多数的内存填充 0, 你可以使用.zero指令.
例子 :
s :
.long 1, 2, 3 ;声明 3 个大小为 4 字节的数据 1, 2, 3. 内存中 s+8 这个标签所对应的数据就是 3.
barr:
.zero 10 ;从 barr 这个标签的位置开始, 声明 10 个字节的数据, 这些数据被初始化为 0.
str :
.string "hello" ;从 str 这个标签的位置开始, 声明 6 个字节的数据, 即 hello 对应的 ASCII 值, 这最后还跟有一个 nul(0) 字节.



3.3.3.2 内存寻址
现代x86兼容处理器能够寻址高达 2^32 字节的内存 : 内存地址为 32 位宽. 在上面的示例中,我们使用标签来引用内存区域,这些标签实际上被 32 位数据的汇编程序替换,这些数据指定了内存中的地址. 除了支持通过标签(即常数值)引用存储区域之外,x86提供了一种灵活的计算和引用内存地址的方案 :最多可将两个32位寄存器和一个32位有符号常量相加,以计算存储器地址. 其中一个寄存器可以选择预先乘以 2, 4 或 8.
寻址模式可以和许多 x86 指令一起使用 ( 我们将在下一节对它们进行讲解 ). 这里我们用mov指令在寄存器和内存中移动数据当作例子. 这个指令有两个参数, 第一个是数据的来源, 第二个是数据的去向.
一些mov的例子 :
mov (%ebx), %eax ;从 EBX 中的内存地址加载 4 个字节的数据到 EAX, 就是把 EBX 中的内容当作标签, 这个标签在内存中对应的数据放到 EAX 中
;后面如果没有说明的话, (%ebx)就表示寄存器ebx中存储的内容
mov %ebx, var(,1) ; 将 EBX 中的 4 个字节大小的数据移动的内存中标签为 var 的地方去.( var 是一个 32 位常数).
mov (%esi, %ebx, 4), %edx ;将内存中标签为 ESI+4*EBX 所对应的 4 个字节大小的数据移动到 EDX中.
一些错误的例子:
mov (%ebx, %ecx, -1), %eax ;这个只能把寄存器中的值加上一遍.
mov %ebx,(%eax, %esi, %edi, 1) ;在地址计算中, 最多只能出现 2 个寄存器, 这里却有 3 个寄存器.
3.3.3.3 操作后缀
通常, 给定内存地址的数据类型可以从引用它的汇编指令推断出来. 例如, 在上面的指令中, 你可以从寄存器操作数的大小来推出其所占的内存大小. 当我们加载一个 32 位的寄存器的时候, 编译器就可以推断出我们用到的内存大小是 4 个字节宽. 当我们将 1 个字节宽的寄存器的值保存到内存中时, 编译器可以推断出我们想要在内存中弄个 1 字节大小的 " 坑 " 来保存我们的数据.
然而在某些情况下, 我们用到的内存中 " 坑 " 的大小是不明确的. 比如说这条指令 mov $2,(%ebx). 这条指令是否应该将 " 2 " 这个值移动到 EBX 中的值所代表的地址 " 坑 " 的单个字节中 ? 也许它表示的是将 32 位整数表示的 2 移动到从地址 EBX 开始的 4 字节. 既然这两个解释都有道理, 但计算机汇编程序必须明确哪个解释才是正确的, 计算机很单纯的, 要么是错的要么是对的. 前缀 b, w, 和 l 就是来解决这个问题的, 它们分别表示 1, 2 和 4 个字节的大小.
举几个例子 :
movb $2, (%ebx) ;将 2 移入到 ebx 中的值所表示的地址单元中.
movw $2, (%ebx) ;将 16 位整数 2 移动到 从 ebx 中的值所表示的地址单元 开始的 2 个字节中;这话有点绕, 所以我故意在里面加了点空格, 方便大家理解.
movl $2,(%ebx) ;将 32 位整数 2 移动到 从 ebx中的值表示的地址单元 开始的 4 个字节中.
3.3.4 指令 Instructions
机器指令通常分为 3 类 : 数据移动指令, 逻辑运算指令和流程控制指令. 在本节中, 我们将讲解每一种类型的 x86 指令以及它们的重要示例. 当然, 我们不可能把 x86 所有指令讲得特别详细, 毕竟篇幅和水平有限. 完整的指令列表, 请参阅 intel 的指令集参考手册.
我们将使用以下符号 :
<reg32 任意的 32 位寄存器 (%eax, %ebx, %ecx, %edx, %esi, %edi, %esp 或者 %eb)
<reg16 任意的 16 位寄存器 (%ax, %bx, %cx 或者 %dx)
<reg8 任意的 8 位寄存器 (%ah, %al, %bh, %bl, %ch, %cl, %dh, %dl)
<reg 任意的寄存器
<mem 一个内存地址, 例如 (%eax), 4+var, (%eax, %ebx, 1)
<con32 32 位常数
<con16 16 位常数
<con8 8 位常数
<con 任意 32位, 16 位或者 8 位常数
在汇编语言中, 用作立即操作数 的所有标签和数字常量 ( 即不在诸如3 (%eax, %ebx, 8)这样的地址计算中 ) 总是以美元符号 $ 为前缀. 需要的时候, 前缀 0x 表示十六进制数, 例如$ 0xABC. 如果没有前缀, 则默认该数字为十进制数.
3.3.4.1 数据移动指令
mov移动
mov 指令将数据从它的第一个参数 ( 即寄存器中的内容, 内存单元中的内容, 或者一个常数值 ) 复制到它的第二个参数 ( 即寄存器或者内存单元 ). 当寄存器到寄存器之间的数据移动是可行的时候, 直接地从内存单元中将数据移动到另一内存单元中是不行的. 在这种需要在内存单元中传递数据的情况下, 它数据来源的那个内存单元必须首先把那个内存单元中的数据加载到一个寄存器中, 然后才可以通过这个寄存器来把数据移动到目标内存单元中.
- 语法
mov <reg, <reg
mov <reg, <mem
mov <mem, <reg
mov <con, <reg
mov <con, <mem
- 例子
mov %ebx, %eax ;将 EBX 中的值复制到 EAX 中
mov $5, var(,1) ;将数字 5 存到字节型内存单元 " var "

push入栈
push指令将它的参数移动到硬件支持的栈内存顶端. 特别地, push 首先将 ESP 中的值减少 4, 然后将它的参数移动到一个 32 位的地址单元 ( %esp ). ESP ( 栈指针 ) 会随着不断入栈从而持续递减, 即栈内存是从高地址单元到低地址单元增长.
- 语法
push <reg32
push <mem
push <con32
- 例子
push %eax ;将 EAX 送入栈
push var(,1) ;将 var 对应的 4 字节大小的数据送入栈中
pop出栈
pop指令从硬件支持的栈内存顶端移除 4 字节的数据, 并把这个数据放到该指令指定的参数中 ( 即寄存器或者内存单元 ). 其首先将内存中 ( %esp ) 的 4 字节数据放到指定的寄存器或者内存单元中, 然后让 ESP + 4.
- 语法
pop <reg32
pop <mem
- 例子
pop %edi ;将栈顶的元素移除, 并放入到寄存器 EDI 中.
pop (%ebx) ;将栈顶的元素移除, 并放入从 EBX 开始的 4 个字节大小的内存单元中.
重点内容 : 栈 栈是一种特殊的存储空间, 特殊在它的访问形式上, 它的访问形式就是最后进入这个空间的数据, 最先出去, 也就是 "先进后出, 后进先出".
lea加载有效地址
lea指令将其第一个参数指定的内存单元 放入到 第二个参数指定的寄存器中. 注意, 该指令不加载内存单元中的内容, 只是计算有效地址并将其放入寄存器. 这对于获得指向存储器区域的指针或者执行简单的算术运算非常有用.
也许这里你会看得一头雾水, 不过你不必担心, 这里有更为通俗易懂的解释.
汇编语言中 lea 指令和 mov 指令的区别 ?
MOV 指令的功能是传送数据,例如 MOV AX,[1000H],作用是将 1000H 作为偏移地址,寻址找到内存单元,将该内存单元中的数据送至 AX;
LEA 指令的功能是取偏移地址,例如 LEA AX,[1000H],作用是将源操作数 [1000H] 的偏移地址 1000H 送至 AX。理解时,可直接将[ ]去掉,等同于 MOV AX,1000H。
再如:LEA BX,[AX],等同于 MOV BX,AX;LEA BX,TABLE 等同于 MOV BX,OFFSET TABLE。
但有时不能直接使用 MOV 代替:
比如:LEA AX,[SI+6] 不能直接替换成:MOV AX,SI+6;但可替换为:
MOV AX,SI
ADD AX,6
两步完成。
- 语法
lea <mem, <reg32
- 例子
lea (%ebx,%esi,8), %edi ;EBX+8*ESI 的值被移入到了 EDI
lea val(,1), %eax ;val 的值被移入到了 EAX
3.3.4.2 逻辑运算指令
add整数相加
add 指令将两个参数相加, 然后将结果存放到第二个参数中. 注意, 参数可以是寄存器,但参数中最多只有一个内存单元. 这话有点绕, 我们直接看语法 :
- 语法
add <reg, <reg
add <mem, <reg
add <reg, <mem
add <con, <reg
add <con, <mem
- 例子
add $10, %eax ;EAX 中的值被设置为了 EAX+10.
addb $10, (%eax) ;往 EAX 中的值 所代表的内存单元地址 加上 1 个字节的数字 10.
sub整数相减
sub指令将第二个参数的值与第一个相减, 就是后面那个减去前面那个, 然后把结果存储到第二个参数. 和add一样, 两个参数都可以是寄存器, 但两个参数中最多只能有一个是内存单元.
- 语法
sub <reg, <reg
sub <mem, <reg
sub <con, <reg
sub <con, <mem
- 例子
sub %ah, %al ;AL 被设置成 AL-AH
sub $216, %eax ;将 EAX 中的值减去 216
inc, dec自增, 自减
inc 指令让它的参数加 1, dec 指令则是让它的参数减去 1.
- 语法
inc <reg
inc <mem
dec <reg
dec <mem
- 例子
dec %eax ;EAX 中的值减去 1
incl var(,1) ;将 var 所代表的 32 位整数加上 1.
imul整数相乘
imul 指令有两种基本格式 : 第一种是 2 个参数的 ( 看下面语法开始两条 ); 第二种格式是 3 个参数的 ( 看下面语法最后两条 ).
2 个参数的这种格式, 先是将两个参数相乘, 然后把结果存到第二个参数中. 运算结果 ( 即第二个参数 ) 必须是一个寄存器.
3 个参数的这种格式, 先是将它的第 1 个参数和第 2 个参数相乘, 然后把结果存到第 3 个参数中, 当然, 第 3 个参数必须是一个寄存器. 此外, 第 1 个参数必须是一个常数.
- 语法
imul <reg32, <reg32
imul <mem, <reg32
imul <con, <reg32, <reg32
imul <con, <mem, <reg32
- 例子
imul (%ebx), %eax ;将 EAX 中的 32 位整数, 与 EBX 中的内容所指的内存单元, 相乘, 然后把结果存到 EAX 中.
imul $25, %edi, %esi ;ESI 被设置为 EDI * 25.
idiv整数相除
idiv只有一个操作数,此操作数为除数,而被除数则为 EDX : EAX 中的内容(一个64位的整数), 除法结果 ( 商 ) 存在 EAX 中, 而所得的余数存在 EDX 中.
- 语法
idiv <reg32
idiv <mem
- 例子
idiv %ebx ;用 EDX : EAX 的值除以 EBX 的值. 商存放在 EAX 中, 余数存放在 EDX 中.
idivw (%ebx) ;将 EDX : EAX 的值除以存储在 EBX 所对应内存单元的 32 位值. 商存放在 EAX 中, 余数存放在 EDX 中.
and, or, xor按位逻辑 与, 或, 异或 运算
这些指令分别对它们的参数进行相应的逻辑运算, 运算结果存到第一个参数中.
- 语法
and <reg, <reg
and <mem, <reg
and <reg, <mem
and <con, <reg
and <con, <mem
or <reg, <reg
or <mem, <reg
or <reg, <mem
or <con, <reg
or <con, <mem
xor <reg, <reg
xor <mem, <reg
xor <reg, <mem
xor <con, <reg
xor <con, <mem
- 例子
and $0x0F, %eax ;只留下 EAX 中最后 4 位数字 (二进制位)
xor %edx, %edx ;将 EDX 的值全部设置成 0
not逻辑位运算 非
对参数进行逻辑非运算, 即翻转参数中所有位的值.
- 语法
not <reg
not <mem
- 例子
not %eax ;将 EAX 的所有值翻转.
neg取负指令
取参数的二进制补码负数. 直接看例子也许会更好懂.
- 语法
neg <reg
neg <mem
- 例子
neg %eax ;EAX → -EAX
shl, shr按位左移或者右移
这两个指令对第一个参数进行位运算, 移动的位数由第二个参数决定, 移动过后的空位拿 0 补上.被移的参数最多可以被移 31 位. 第二个参数可以是 8 位常数或者寄存器 CL. 在任意情况下, 大于 31 的移位都默认是与 32 取模.
- 语法
shl <con8, <reg
shl <con8, <mem
shl %cl, <reg
shl %cl, <mem
shr <con8, <reg
shr <con8, <mem
shr %cl, <reg
shr %cl, <mem
- 例子
shl $1, %eax ;将 EAX 的值乘以 2 (如果最高有效位是 0 的话)
shr %cl, %ebx ;将 EBX 的值除以 2n, 其中 n 为 CL 中的值, 运算最终结果存到 EBX 中.
你也许会想, 明明只是把数字二进制移了 1 位, 结果却是等于这个数字乘以 2.什么情况 ? 这几个位运算的结果和计算机表示数字的原理有关,请看本章附录的计算机数字表示.
3.3.4.3 流程控制指令
x86 处理器有一个指令指针寄存器 ( EIP ), 该寄存器为 32 位寄存器, 它用来在内存中指示我们输入汇编指令的位置. 就是说这个寄存器指向哪个内存单元, 那个单元存储的机器码就是程序执行的指令. 通常它是指向我们程序要执行的 下一条指令. 但是你不能直接操作 EIP 寄存器, 你需要流程控制指令来隐式地给它赋值.
我们使用符号 <label 来当作程序中的标签. 通过输入标签名称后跟冒号, 可以将标签插入 x86 汇编代码文本中的任何位置. 例如 :
mov 8(%ebp), %esi
begin:
xor %ecx, %ecx
mov (%esi), %eax
该代码片段中的第二段被套上了 " begin " 这个标签. 在代码的其它地方, 我们可以用 " begin " 这个标签从而更方便地来引用这段指令在内存中的位置. 这个标签只是用来更方便地表示位置的, 它并不是用来代表某个 32 位值.
jmp跳转指令将程序跳转到参数指定的内存地址, 然后执行该内存地址的指令.
语法
jmp <label
- 例子
jmp begin ;跳转到打了 " begin " 这个标签的地方

jcondition有条件的跳转
这些指令是条件跳转指令, 它们基于一组条件代码的状态, 这些条件代码的状态存放在称为机器状态字 ( machine status word ) 的特殊寄存器中. 机器状态字的内容包括关于最后执行的算术运算的信息. 例如, 这个字的一个位表示最后的结果是否为 0. 另一个位表示最后结果是否为负数. 基于这些条件代码, 可以执行许多条件跳转. 例如, 如果最后一次算术运算结果为 0, 则 jz 指令就是跳转到指定参数标签. 否则, 程序就按照流程进入下一条指令.
许多条件分支的名称都是很直观的, 这些指令的运行, 都和一个特殊的比较指令有关, cmp( 见下文 ). 例如, 像 jle 和 jne 这种指令, 它们首先对参数进行 cmp 操作.
- 语法
je <label ;当相等的时候跳转
jne <label ;当不相等的时候跳转
jz <label ;当最后结果为 0 的时候跳转
jg <label ;当大于的时候跳转
jge <label ;当大于等于的时候跳转
jl <label ;当小于的时候跳转
jle <label ;当小于等于的时候跳转
- 例子
cmp %ebx, %eax
jle done
;如果 EAX 的值小于等于 EBX 的值, 就跳转到 " done " 标签, 否则就继续执行下一条指令.

cmp比较指令
比较两个参数的值, 适当地设置机器状态字中的条件代码. 此指令与sub指令类似,但是cmp不用将计算结果保存在操作数中.
- 语法
cmp <reg, <reg
cmp <mem, <reg
cmp <reg, <mem
cmp <con, <reg
- 例子
cmpb $10, (%ebx)
jeq loop
;如果 EBX 的值等于整数常量 10, 则跳转到标签 " loop " 的位置.

call, ret子程序调用与返回
这两个指令实现子程序的调用和返回. call 指令首先将当前代码位置推到内存中硬件支持的栈内存上 ( 请看 push 指令 ), 然后无条件跳转到标签参数指定的代码位置. 与简单的 jmp 指令不同, call 指令保存了子程序完成时返回的位置. 就是 call 指令结束后, 返回到调用之前的地址.
ret 指令实现子程序的返回. 该指令首先从栈中取出代码 ( 类似于 pop 指令 ). 然后它无条件跳转到检索到的代码位置.
- 语法
call <label
ret
3.3.5 调用约定 Calling Convention
为了方便不同的程序员去分享代码和运行库, 并简化一般子程序的使用, 程序员们通常会遵守一定的约定 ( Calling Convention ). 调用约定是关于如何从例程调用和返回的协议. 例如,给定一组调用约定规则,程序员不需要检查子例程的定义来确定如何将参数传递给该子例程. 此外,给定一组调用约定规则,可以使高级语言编译器遵循规则,从而允许手动编码的汇编语言例程和高级语言例程相互调用.
我们将讲解被广泛使用的 C 语言调用约定. 遵循此约定将允许您编写可从 C ( 和C ++ ) 代码安全地调用的汇编语言子例程, 并且还允许您从汇编语言代码调用 C 函数库.
C 调用约定很大程度上取决于使用硬件支持的栈内存. 它基于 push, pop, call 和 ret 指令. 子程序的参数在栈上传递. 寄存器保存在栈中, 子程序使用的局部变量放在栈中. 在大多数处理器上实现的高级过程语言都使用了类似的调用约定.
调用约定分为两组. 第一组规则是面向子例程的调用者 ( Caller ) 的, 第二组规则面向子例程的编写者, 即被调用者 ( Callee ). 应该强调的是, 错误地遵守这些规则会导致程序的致命错误, 因为栈将处于不一致的状态; 因此, 在你自己的子例程中实现调用约定的时候, 务必当心.

将调用约定可视化的一种好方法是, 在子例程执行期间画一个栈内存附近的图. 图 2 描绘了在执行具有三个参数和三个局部变量的子程序期间栈的内容. 栈中描绘的单元都是 32 位内存单元, 因此这些单元的内存地址相隔 4 个字节. 第一个参数位于距基指针 8 个字节的偏移处. 在栈参数的上方 ( 和基指针下方 ), call 指令在这放了返回地址, 从而导致从基指针到第一个参数有额外 4 个字节的偏移量. 当 ret 指令用于从子程序返回时, 它将跳转到栈中的返回地址.
3.3.5.1 调用者约定 Caller Rules
要进行子程序调用, 调用者应该 :
在调用子例程之前, 调用者应该保存指定调用者保存 ( Caller-saved )的某些寄存器的内容. 调用者保存的寄存器是 EAX, ECX, EDX. 由于被调用的子程序可以修改这些寄存器, 所以如果调用者在子例程返回后依赖这些寄存器的值, 调用者必须将这些寄存器的值入栈, 然后就可以在子例程返回后恢复它们.
要把参数传递给子例程, 你可以在调用之前把参数入栈. 参数的入栈顺序应该是反着的, 就是最后一个参数应该最先入栈. 随着栈内存地址增大, 第一个参数将存储在最低的地址, 在历史上, 这种参数的反转用于允许函数传递可变数量的参数.
要调用子例程, 请使用
call指令. 该指令将返回地址存到栈上, 并跳转到子程序的代码. 这个会调用子程序, 这个子程序应该遵循下面的被调用者约定.
子程序返回后 ( 紧跟调用指令后 ), 调用者可以期望在寄存器 EAX 中找到子例程的返回值. 要恢复机器状态 ( machine state ), 调用者应该 :
- 从栈中删除参数, 这会把栈恢复到调用之前的状态.
把 EAX, ECX, EDX 之前入栈的内容给出栈, 调用者可以假设子例程没有修改其它寄存器.
例子
下面的代码就是个活生生的例子, 它展示了遵循约定的函数调用. 调用者正在调用一个带有 3 个整数参数的函数 myFunc. 第一个参数是 EAX, 第二个参数是常数 216; 第三个参数位于 EBX 的值所代表的内存地址.
push (%ebx) ;最后一个参数最先入栈
push $216 ;把第二个参数入栈
push %eax ;第一个参数最后入栈
call myFunc ;调用这个函数 ( 假设以 C 语言的模式命名 )
add $12, %esp
注意, 在调用返回后, 调用者使用 add 指令来清理栈内存. 我们栈内存中有 12 个字节 ( 3 个参数, 每个参数 4 个字节 ), 然后栈内存地址增大. 因此, 为了摆脱掉这些参数, 我们可以直接往栈里面加个 12.
myFunc 生成的结果现在可以有用于寄存器 EAX. 调用者保存 ( Caller-saved ) 的寄存器 ( ECX, EDX ) 的值可能已经被修改. 如果调用者在调用之后使用它们,则需要在调用之前将它们保存在堆栈中并在调用之后恢复它们. 说白了就是把栈这个玩意当作临时存放点.
3.3.5.2 被调用者约定 Callee Rules
子例程的定义应该遵循子例程开头的以下规则 :
- 1.将 EBP 的值入栈, 然后用下面的指示信息把 ESP 的值复制到 EBP 中 :
push %ebp
mov %esp, %ebp
这个初始操作保留了基指针 EBP. 按照约定, 基指针作为栈上找到参数和变量的参考点. 当子程序正在执行的时候, 基指针保存了从子程序开始执行是的栈指针值的副本. 参数和局部变量将始终位于远离基指针值的已知常量偏移处. 我们在子例程的开头推送旧的基指针值,以便稍后在子例程返回时为调用者恢复适当的基指针值. 记住, 调用者不希望子例程修改基指针的值. 然后我们把栈指针移动到 EBP 中, 以获取访问参数和局部变量的参考点.
2.接下来, 通过在栈中创建空间来分配局部变量. 回想一下, 栈会向下增长, 因此要在栈顶部创建空间, 栈指针应该递减. 栈指针递减的数量取决于所需局部变量的数量和大小. 例如, 如果需要 3 个局部整数 ( 每个 4 字节 ), 则需要将堆栈指针递减 12, 从而为这些局部变量腾出空间 ( 即sub $12, %esp ). 和参数一样, 局部变量将位于基指针的已知偏移处.
3.接下来, 保存将由函数使用的 被调用者保存的 ( Callee-saved ) 寄存器的值. 要存储寄存器, 请把它们入栈. 被调用者保存 ( Callee-saved ) 的寄存器是 EBX, EDI 和 ESI ( ESP 和 EBP 也将由调用约定保留, 但在这个步骤中不需要入栈 ).
在完成这 3 步之后, 子例程的主体可以继续. 返回子例程的时候, 必须遵循以下步骤 :
将返回值保存在 EAX 中.
恢复已经被修改的任何被调用者保存 ( Callee-saved ) 的寄存器 ( EDI 和 ESI ) 的旧值. 通过出栈来恢复它们. 当然应该按照相反的顺序把它们出栈.
释放局部变量. 显而易见的法子是把相应的值添加到栈指针 ( 因为空间是通过栈指针减去所需的数量来分配的 ). 事实上呢, 解除变量释放的错误的方法是将基指针中的值移动到栈指针 :
mov %ebp, %esp. 这个法子有效, 是因为基指针始终包含栈指针在分配局部变量之前包含的值.在返回之前, 立即通过把 EBP 出栈来恢复调用者的基指针值. 回想一下, 我们在进入子程序的时候做的第一件事是推动基指针保存它的旧值.
- 最后, 通过执行
ret指令返回. 这个指令将从栈中找到并删除相应的返回地址 ( call 指令保存的那个 ).
请注意, 被调用者的约定完全被分成了两半, 简直是彼此的镜像. 约定的前半部分适用于函数开头, 并且通常被称为定义函数的序言 ( prologue ) .这个约定的后半部分适用于函数结尾, 因此通常被称为定义函数的结尾 ( epilogue ).
- 例子
这是一个遵循被调用者约定的例子 :
;启动代码部分
.text
;将 myFunc 定义为全局 ( 导出 ) 函数
.globl myFunc
.type myFunc, @function
myFunc :
;子程序序言
push %ebp ;保存基指针旧值
mov %esp, %ebp ;设置基指针新值
sub $4, %esp ;为一个 4 字节的变量腾出位置
push %edi
push %esi ;这个函数会修改 EDI 和 ESI, 所以先给它们入栈
;不需要保存 EBX, EBP 和 ESP
;子程序主体
mov 8(%ebp), %eax ;把参数 1 的值移到 EAX 中
mov 12(%ebp), %esi ;把参数 2 的值移到 ESI 中
mov 16(%ebp), %edi ;把参数 3 的值移到 EDI 中
mov %edi, -4(%ebp) ;把 EDI 移给局部变量
add %esi, -4(%ebp) ;把 ESI 添加给局部变量
add -4(%ebp), %eax ;将局部变量的内容添加到 EAX ( 最终结果 ) 中
;子程序结尾
pop %esi ;恢复寄存器的值
pop %edi
mov %ebp, %esp ;释放局部变量
pop %ebp ;恢复调用者的基指针值
ret
子程序序言执行标准操作, 即在 EBP ( 基指针 ) 中保存栈指针的副本, 通过递减栈指针来分配局部变量, 并在栈上保存寄存器的值.
在子例程的主体中, 我们可以看到基指针的使用. 在子程序执行期间, 参数和局部变量都位于与基指针的常量偏移处. 特别地, 我们注意到, 由于参数在调用子程序之前被放在栈中, 因此它们总是位于栈基指针 ( 即更高的地址 ) 之下. 子程序的第一个参数总是可以在内存地址 ( EBP+8 ) 找到, 第二个参数在 ( EBP+12 ), 第三个参数在 ( EBP+16). 类似地, 由于在设置基指针后分配局部变量, 因此它们总是位于栈上基指针 ( 即较低地址 ) 之上. 特别是, 第一个局部变量总是位于 ( EBP-4 ), 第二个位于 ( EBP-8 ), 以此类推. 这种基指针的常规使用, 让我们可以快速识别函数内部局部变量和参数的使用.
函数结尾基本上是函数序言的镜像. 从栈中恢复调用者的寄存器值, 通过重置栈指针来释放局部变量, 恢复调用者的基指针值, 并用 ret 指令返回调用者中的相应代码位置, 从哪来回哪去.
3.4 x64 汇编基础
3.4.1 导语
x86-64 (也被称为 x64 或者 AMD64) 是 64 位版本的 x86/IA32 指令集. 以下是我们关于 CS107 相关功能的概述.
3.4.2 寄存器 Registers
下图列出了常用的寄存器 ( 16个通用寄存器加上 2 个特殊用途寄存器 ). 每个寄存器都是 64 bit 宽, 它们的低 32, 16, 8 位都可以看成相应的 32, 16, 8 位寄存器, 并且都有其特殊名称. 一些寄存器被设计用来完成某些特殊目的, 比如 %rsp 被用来作为栈指针, %rax 作为一个函数的返回值. 其他寄存器则都是通用的, 但是一般在使用的时候, 还是要取决于调用者 ( Caller-owned )或者被调用者 ( Callee-owned ). 如果函数 binky 调用了 winky, 我们称 binky 为调用者, winky 为被调用者. 例如, 用于前 6 个参数和返回值的寄存器都是被调用者所有的 ( Callee-owned ). 被调用者可以任意使用这些寄存器, 不用任何预防措施就可以随意覆盖里面的内容. 如果 %rax 存着调用者想要保留的值, 则 Caller 必须在调用之前将这个 %rax 的值复制到一个 " 安全 " 的位置. 被调用者拥有的 ( Callee-owned ) 寄存器非常适合一些临时性的使用. 相反, 如果被调用者打算使用调用者所拥有的寄存器, 那么被调用者必须首先把这个寄存器的值存起来, 然后在退出调用之前把它恢复. 调用者拥有的 ( Caller-owned ) 寄存器用于保存调用者的本地状态 ( local state ), 所以这个寄存器需要在进一步的函数调用中被保留下来.

3.4.3 寻址模式 Addressing modes
正由于它的 CISC 特性, X86-64 支持各种寻址模式. 寻址模式是计算要读或写的内存地址的表达式. 这些表达式用作mov指令和访问内存的其它指令的来源和去路. 下面的代码演示了如何在每个可用的寻址模式中将 立即数 1 写入各种内存位置 :
movl $1, 0x604892 ;直接写入, 内存地址是一个常数
movl $1, (%rax) ;间接写入, 内存地址存在寄存器 %rax 中
movl $1, -24(%rbp) ;使用偏移量的间接写入
;公式 : (address = base %rbp + displacement -24)
movl $1, 8(%rsp, %rdi, 4) ;间接写入, 用到了偏移量和按比例放大的索引 ( scaled-index )
;公式 : (address = base %rsp + displ 8 + index %rdi * scale 4)
movl $1, (%rax, %rcx, 8) ;特殊情况, 用到了按比例放大的索引 ( scaled-index ), 假设偏移量 ( displacement ) 为 0
movl $1, 0x8(, %rdx, 4) ;特殊情况, 用到了按比例放大的索引 ( scaled-index ), 假设基数 ( base ) 为 0
movl $1, 0x4(%rax, %rcx) ;特殊情况, 用到了按比例放大的索引 ( scaled-index ), 假设比例 ( scale ) 为0
3.4.4 通用指令 Common instructions
先说下指令后缀, 之前讲过这里就重温一遍 : 许多指令都有个后缀 ( b, w, l, q ) , 后缀指明了这个指令代码所操纵参数数据的位宽 ( 分别为 1, 2, 4 或 8 个字节 ). 当然, 如果可以从参数确定位宽的时候, 后缀可以被省略. 例如呢, 如果目标寄存器是 %eax, 则它必须是 4 字节宽, 如果是 %ax 寄存器, 则必须是 2 个字节, 而 %al 将是 1 个字节. 还有些指令, 比如 movs 和 movz 有两个后缀 : 第一个是来源参数, 第二个是去路. 这话乍一看让人摸不着头脑, 且听我分析. 例如, movzbl 这个指令把 1 个字节的来源参数值移动到 4 个字节的去路.
当目标是子寄存器 ( sub-registers ) 时, 只有子寄存器的特定字节被写入, 但有一个例外 : 32 位指令将目标寄存器的高 32 位设置为 0.
mov 和 lea 指令
到目前为止, 我们遇到的最频繁的指令就是 mov, 而它有很多变种. 关于 mov 指令就不多说了, 和之前 32 位 x86 的没什么区别. lea 指令其实也没什么好说的, 上一节都有, 这里就不废话了.
这里写几个比较有意思的例子 :
mov 8(%rsp), %eax ;%eax = 从地址 %rsp + 8 读取的值
lea 0x20(%rsp), %rdi ;%rdi = %rsp + 0x20
lea (%rdi,%rdx,1), %rax ;%rax = %rdi + %rdx
在把较小位宽的数据移动复制到较大位宽的情况下, movs 和 movz 这两个变种指令用于指定怎么样去填充字节, 因为你是一个小东西被移到了一个大空间, 肯定还有地方是空的, 所以空的地方要填起来, 拿 0 或者 符号扩展 ( sign-extend ) 来填充.
movsbl %al, %edx ;把 1 个字节的 %al, 符号扩展 复制到 4 字节的 %edx
movzbl %al, %edx ;把 1 个字节的 %al, 零扩展 ( zero-extend ) 复制到 4 字节的 %edx
有个特殊情况要注意, 默认情况下, 将 32 位值写入寄存器的 mov 指令, 也会将寄存器的高 32 位归零, 即隐式零扩展到位宽 q. 这个解释了诸如 mov %ebx, %ebx 这种指令, 这些指令看起来很奇怪, 但实际上这是用于从 32 位扩展到 64 位. 因为这个是默认的, 所以我们不用显式的 movzlq 指令. 当然, 有一个 movslq 指令也是从 32 位符号扩展到 64 位.
cltq 指令是一个在 %rax 上运行的专用移动指令. 这个没有参数的指令在 %rax 上进行符号扩展, 源位宽为 L, 目标位宽为 q.
cltq ;在 %rax 上运行,将 4 字节 src 符号扩展为 8 字节 dst,用于 movslq %eax,%rax
算术和位运算
二进制的运算一般是两个参数, 其中第二个参数既是我们指令运算的来源, 也是去路的来源, 就是说我们把运算结果存在第二个参数里. 我们的第一个参数可以是立即数常数, 寄存器或者内存单元. 第二个参数必须是寄存器或者内存. 这两个参数中, 最多只有一个参数是内存单元, 当然也有的指令只有一个参数, 这个参数既是我们运算数据的来源, 也是我们运算数据的去路, 它可以是寄存器或者内存. 这个我们上一节讲了, 这里回顾一下. 许多算术指令用于有符号和无符号类型,也就是带符号加法和无符号加法都使用相同的指令. 当需要的时候, 参数设置的条件代码可以用来检测不同类型的溢出.
add src, dst ;dst = dst + src
sub src, dst ;dst = dst - src
imul src, dst ;dst = dst * src
neg dst ;dst = -dst ( 算术取反 )
and src, dst ;dst = dst & src
or src, dst ;dst = dst | src
xor src, dst ;dst = dst ^ src
not dst ;dst = ~dst ( 按位取反 )
shl count, dst ;dst <<= count ( 按 count 的值来左移 ), 跟这个相同的是`sal`指令
sar count, dst ;dst = count ( 按 count 的值来算术右移 )
shr count, dst ;dst = count ( 按 count 的值来逻辑右移 )
;某些指令有特殊情况变体, 这些变体有不同的参数
imul src ;一个参数的 imul 指令假定 %rax 中其他参数计算 128 位的结果, 在 %rdx 中存储高 64 位, 在 %rax 中存储低 64 位.
shl dst ;dst <<= 1 ( 后面没有 count 参数的时候默认是移动 1 位, `sar`, `shr`, `sal` 指令也是一样 )
这些指令上一节都讲过, 这里稍微提一下.
流程控制指令
有一个特殊的 %eflags 寄存器, 它存着一组被称为条件代码的布尔标志. 大多数的算术运算会更新这些条件代码. 条件跳转指令读取这些条件代码之后, 再确定是否执行相应的分支指令. 条件代码包括 ZF( 零标志 ), SF( 符号标志 ), OF( 溢出标志, 有符号 ) 和 CF( 进位标志, 无符号 ). 例如, 如果结果为 0 , 则设置 ZF, 如果操作溢出 ( 进入符号位 ), 则设置 OF.
这些指令一般是先执行 cmp 或 test 操作来设置标志, 然后再跟跳转指令变量, 该变量读取标志来确定是采用分支代码还是继续下一条代码. cmp 或 test 的参数是立即数, 寄存器或者内存单元 ( 最多只有一个内存参数 ). 条件跳转有 32 中变体, 其中几种效果是一样的. 下面是一些分支指令.
cmpl op2, op1 ;运算结果 = op1 - op2, 丢弃结果然后设置条件代码
test op2, op1 ;运算结果 = op1 & op2, 丢弃结果然后设置条件代码
jmp target ;无条件跳跃
je target ;等于时跳跃, 和它相同的还有 jz, 即jump zero ( ZF = 1 )
jne target ;不相等时跳跃, 和它相同的还有 jnz, 即 jump non zero ( ZF = 0 )
jl target ;小于时跳跃, 和它相同的还有 jnge, 即 jump not greater or equal ( SF != OF )
jle target ;小于等于时跳跃, 和它相同的还有 jng, 即 jump not greater ( ZF = 1 or SF != OF )
jg target ;大于时跳跃, 和它相同的还有 jnle, 即 jump not less or equal ( ZF = 0 and SF = OF )
jge target ;大于等于时跳跃, 和它相同的还有 jnl, 即 jump not less ( SF = OF )
ja target ;跳到上面, 和它相同的还有 jnbe, 即 jump not below or equal ( CF = 0 and ZF = 0 )
jb target ;跳到下面, 和它相同的还有 jnae, 即 jump not above or equal ( CF = 1 )
js target ;SF = 1 时跳跃
jns target ;SF = 0 时跳跃
其实你也会发现这里大部分上一节都讲过, 这里我们可以再来一遍巩固一下.
setx和movx
还有两个指令家族可以 读取/响应 当前的条件代码. setx 指令根据条件 x 的状态将目标寄存器设置为 0 或 1. cmovx 指令根据条件 x 是否成立来有条件地执行 mov. x 是任何条件变量的占位符, 就是说 x 可以用这些来代替 : e, ne, s, ns. 它们的意思上面也都说过了.
sete dst ;根据 零/相等( zero/equal ) 条件来把 dst 设置成 0 或 1
setge dst ;根据 大于/相等( greater/equal ) 条件来把 dst 设置成 0 或 1
cmovns src, dst ;如果 ns 条件成立, 则继续执行 mov
cmovle src, dst ;如果 le 条件成立, 则继续执行 mov
对于 setx 指令, 其目标必须是单字节寄存器 ( 例如 %al 用于 %rax 的低字节 ). 对于 cmovx 指令, 其来源和去路都必须是寄存器.
函数调用与栈
%rsp 寄存器用作 " 栈指针 "; push 和 pop 用于添加或者删除栈内存中的值. push 指令只有一个参数, 这个参数是立即数常数, 寄存器或内存单元. push 指令先把 %rsp 的值递减, 然后将参数复制到栈内存上的 tompost. pop 指令也只有一个参数, 即目标寄存器. pop 先把栈内存最顶层的值复制到目标寄存器, 然后把 %rsp 递增. 直接调整 %rsp, 以通过单个参数添加或删除整个数组或变量集合也是可以的. 但注意, 栈内存是朝下增长 ( 即朝向较低地址 ).
push %rbx ;把 %rbx 入栈
pushq $0x3 ;把立即数 3 入栈
sub $0x10, %rsp ;调整栈指针以空出 16 字节
pop %rax ;把栈中最顶层的值出栈到寄存器 %rax 中
add $0x10, %rsp ;调整栈指针以删除最顶层的 16 个字节
函数之间是通过互相调用返回来互相控制的. callq 指令有一个参数, 即被调用的函数的地址. 它将返回来的地址入栈, 这个返回来的地址即 %rip 当前的值, 也即是调用函数后的下一条指令. 然后这个指令让程序跳转到被调用的函数的地址. retq 指令把刚才入栈的地址给出栈, 让它回到 %rip 中, 从而让程序在保存的返回地址处重新开始, 就是说你中途跳到别的地方去, 你回来的时候要从你跳的那个地方重新开始.
当然, 你如果要设置这种函数间的互相调用, 调用者需要将前六个参数放入寄存器 %rdi, %rsi, %rdx, %rcx, %r8 和 %r9 ( 任何其它参数都入栈 ), 然后再执行调用指令.
mov $0x3, %rdi ;第一个参数在 %rdi 中
mov $0x7, %rsi ;第二个参数在 %rsi 中
callq binky ;把程序交给 binky 控制
当被调用者那个函数完事的时候, 这个函数将返回值 ( 如果有的话 ) 写入 %rax, 然后清理栈内存, 并使用 retq 指令把程序控制权交还给调用者.
mov $0x0, %eax ;将返回值写入 %rax
add $0x10, %rsp ;清理栈内存
retq ;交还控制权, 跳回去
这些分支跳转指令的目标通常是在编译时确定的绝对地址. 但是, 有些情况下直到运行程序的时候, 我们才知道目标的绝对内存地址. 例如编译为跳转表的 switch 语句或调用函数指针时. 对于这些, 我们先计算目标地址, 然后把地址存到寄存器中, 然后用 分支/调用( branch/call ) 变量 je *%rax 或 callq *%rax 从指定寄存器中读取目标地址.
当然还有更简单的方法, 就是上一节讲的打标签.
3.4.5 汇编和 gdb
调试器 ( debugger ) 有许多功能, 这可以让你可以在程序中追踪和调试代码. 你可以通过在其名称上加个 $ 来打印寄存器中的值, 或者使用命令 info reg 转储所有寄存器的值 :
(gdb) p $rsp
(gdb) info reg
disassemble 命令按照名称打印函数的反汇编. x 命令支持 i 格式, 这个格式把内存地址的内容解释为编码指令 ( 解码 ).
(gdb) disassemble main //反汇编, 然后打印所有 main 函数的指令
(gdb) x/8i main //反汇编, 然后打印开始的 8 条指令
你可以通过在函数中的直接地址或偏移量为特定汇编指令设置断点.
(gdb) b *0x08048375
(gdb) b *main+7 //在 main+7个字节这里设置断点
你可以用 stepi 和 nexti 命令来让程序通过指令 ( 而不是源代码 ) 往前执行.
(gdb) stepi
(gdb) nexti
3.5 ARM汇编基础
3.5.1 引言
本章所讲述的是在 GNU 汇编程序下的 ARM 汇编快速指南,而所有的代码示例都会采用下面的结构:
[< 标签 label :] {<指令 instruction or directive } @ 注释 comment
在 GNU 程序中不需要缩进指令。程序的标签是由冒号识别而与所处的位置无关。 就通过一个简单的程序来介绍:
.section .text, "x"
.global add @给符号添加外部链接
add:
ADD r0, r0, r1 @添加输入参数
MOV pc, lr @从子程序返回
@程序结束
它定义的是一个返回总和函数 “ add ”,允许两个输入参数。通过了解这个程序实例,想必接下来这类程序的理解我们也能够很好的的掌握。
3.5.2 ARM 的 GNU 汇编程序指令表
在 GNU 汇编程序下的 ARM 指令集涵括如下:
| GUN 汇编程序指令 | 描述 |
|---|---|
.ascii "<string>" |
将字符串作为数据插入到程序中 |
.asciz "<string>" |
与 .ascii 类似,但跟随字符串的零字节 |
.balign <power_of_2> {,<fill_value>{,<max_padding>} } |
将地址与 <power_of_2> 字节对齐。 汇编程序通过添加值 <fill_value> 的字节或合适的默认值来对齐. 如果需要超过 <max_padding> 这个数字来填充字节,则不会发生对齐( 类似于armasm 中的 ALIGN ) |
.byte <byte1> {,<byte2> } … |
将一个字节值列表作为数据插入到程序中 |
.code <number_of_bits> |
以位为单位设置指令宽度。 使用 16 表示 Thumb,32 表示 ARM 程序( 类似于 armasm 中的 CODE16 和 CODE32 ) |
.else |
与.if和 .endif 一起使用( 类似于 armasm 中的 ELSE ) |
.end |
标记程序文件的结尾( 通常省略 ) |
.endif |
结束条件编译代码块 - 参见.if,.ifdef,.ifndef( 类似于 armasm 中的 ENDIF ) |
.endm |
结束宏定义 - 请参阅 .macro( 类似于 armasm 中的 MEND ) |
.endr |
结束重复循环 - 参见 .rept 和 .irp(类似于 armasm 中的 WEND ) |
.equ <symbol name>, <vallue> |
该指令设置符号的值( 类似于 armasm 中的 EQU ) |
.err |
这个会导致程序停止并出现错误 |
.exitm |
中途退出一个宏 - 参见 .macro( 类似于 armasm 中的 MEXIT ) |
.global <symbol> |
该指令给出符号外部链接( 类似于 armasm 中的 MEXIT )。 |
.hword <short1> {,<short2> }... |
将16位值列表作为数据插入到程序中( 类似于 armasm 中的 DCW ) |
.if <logical_expression> |
把一段代码变成前提条件。 使用 .endif 结束代码块( 类似于 armasm中的 IF )。 另见 .else |
.ifdef <symbol> |
如果定义了 <symbol>,则包含一段代码。 结束代码块用 .endif, 这就是个条件判断嘛, 很简单的. |
.ifndef <symbol> |
如果未定义 <symbol>,则包含一段代码。 结束代码块用 .endif, 同上. |
.include "<filename>" |
包括指定的源文件, 类似于 armasm 中的 INCLUDE 或 C 中的#include |
.irp <param> {,<val 1>} {,<val_2>} ... |
为值列表中的每个值重复一次代码块。 使用 .endr 指令标记块的结尾。 在里面重复代码块,使用 \<param> 替换关联的代码块值列表中的值。 |
.macro <name> {<arg_1>} {,< arg_2>} ... {,<arg_N>} |
使用 N 个参数定义名为<name>的汇编程序宏。宏定义必须以 .endm 结尾。 要在较早的时候从宏中逃脱,请使用 .exitm。 这些指令是类似于 armasm 中的 MACRO,MEND 和MEXIT。 你必须在虚拟宏参数前面加 \. |
.rept <number_of_times> |
重复给定次数的代码块。 以.endr结束。 |
<register_name> .req <register_name> |
该指令命名一个寄存器。 它与 armasm 中的 RN 指令类似,不同之处在于您必须在右侧提供名称而不是数字(例如,acc .req r0) |
.section <section_name> {,"<flags> "} |
启动新的代码或数据部分。 GNU 中有这些部分:.text代码部分;.data初始化数据部分和.bss未初始化数据部分。 这些部分有默认值flags和链接器理解默认名称(与armasm指令AREA类似的指令)。 以下是 ELF 格式文件允许的 .section标志:a 表示 allowable section w 表示 writable section x 表示 executable section |
.set <variable_name>, <variable_value> |
该指令设置变量的值。 它类似于 SETA。 |
.space <number_of_bytes> {,<fill_byte> } |
保留给定的字节数。 如果指定了字节,则填充零或 <fill_byte>(类似于 armasm 中的 SPACE) |
.word <word1> {,<word2>}... |
将 32 位字值列表作为数据插入到程序集中(类似于 armasm 中的 DCD)。 |
3.5.3 寄存器名称
通用寄存器:
%r0 - %r15
fp 寄存器:
%f0 - %f7
临时寄存器:
%r0 - %r3, %r12
保存寄存器:
%r4 - %r10
堆栈 ptr 寄存器:
%sp
帧 ptr 寄存器:
%fp
链接寄存器:
%lr
程序计数器:
%ip
状态寄存器:
$psw
状态标志寄存器:
xPSR
xPSR_all
xPSR_f
xPSR_x
xPSR_ctl
xPSR_fs
xPSR_fx
xPSR_fc
xPSR_cs
xPSR_cf
xPSR_cx
3.5.4 汇编程序特殊字符/语法
内联评论字符: '@'
行评论字符: '#'
语句分隔符: ';'
立即操作数前缀: '#' 或 '$'
3.5.5 arm程序调用标准
参数寄存器 :%a0 - %a4(别名为%r0 - %r4)
返回值regs :%v1 - %v6(别名为%r4 - %r9)
3.5.6 寻址模式
addr 绝对寻址模式
%rn 寄存器直接寻址
[%rn] 寄存器间接寻址或索引
[%rn,#n] 基于寄存器的偏移量
上述 "rn" 指任意寄存器,但不包括控制寄存器。
3.5.7 机器相关指令
| 指令 | 描述 |
|---|---|
| .arm | 使用arm模式进行装配 |
| .thumb | 使用thumb模式进行装配 |
| .code16 | 使用thumb模式进行装配 |
| .code32 | 使用arm模式进行组装 |
| .force_thumb Force | thumb模式(即使不支持) |
| .thumb_func | 将输入点标记为thumb编码(强制bx条目) |
| .ltorg | 启动一个新的文字池 |
3.6 MIPS汇编基础
数据类型和常量
数据类型:
指令全是32位
字节(8位),半字(2字节),字(4字节)
一个字符需要1个字节的存储空间
整数需要1个字(4个字节)的存储空间
常量:
按原样输入的数字。例如 4
用单引号括起来的字符。例如 'b'
用双引号括起来的字符串。例如 “A string”
寄存器
32个通用寄存器
寄存器前面有 $
两种格式用于寻址:
使用寄存器号码,例如
$ 0到$ 31使用别名,例如
$ t1,$ sp特殊寄存器 Lo 和 Hi 用于存储乘法和除法的结果
- 不能直接寻址; 使用特殊指令
mfhi( “ 从 Hi 移动 ” )和mflo( “ 从 Lo 移动 ” )访问的内容
- 不能直接寻址; 使用特殊指令
栈从高到低增长
| 寄存器 | 别名 | 用途 |
|---|---|---|
$0 |
$zero |
常量0(constant value 0) |
$1 |
$at |
保留给汇编器(Reserved for assembler) |
$2-$3 |
$v0-$v1 |
函数调用返回值(values for results and expression evaluation) |
$4-$7 |
$a0-$a3 |
函数调用参数(arguments) |
$8-$15 |
$t0-$t7 |
暂时的(或随便用的) |
$16-$23 |
$s0-$s7 |
保存的(或如果用,需要SAVE/RESTORE的)(saved) |
$24-$25 |
$t8-$t9 |
暂时的(或随便用的) |
$26~$27 |
$k0~$k1 |
保留供中断/陷阱处理程序使用 |
$28 |
$gp |
全局指针(Global Pointer) |
$29 |
$sp |
堆栈指针(Stack Pointer) |
$30 |
$fp |
帧指针(Frame Pointer) |
$31 |
$ra |
返回地址(return address) |
再来说一说这些寄存器 :
zero 它一般作为源寄存器,读它永远返回 0,也可以将它作为目的寄存器写数据,但效果等于白写。为什么单独拉一个寄存器出来返回一个数字呢?答案是为了效率,MIPS 的设计者只允许在寄存器内执行算术操作,而不允许直接操作立即数。所以对最常用的数字 0 单独留了一个寄存器,以提高效率
at 该寄存器为给编译器保留,用于处理在加载 16 位以上的大常数时使用,编译器或汇编程序需要把大常数拆开,然后重新组合到寄存器里。系统程序员也可以显式的使用这个寄存器,有一个汇编 directive 可被用来禁止汇编器在 directive 之后再使用 at 寄存器。
v0, v1.这两个很简单,用做函数的返回值,大部分时候,使用 v0 就够了。如果返回值的大小超过 8 字节,那就需要分配使用堆栈,调用者在堆栈里分配一个匿名的结构,设置一个指向该参数的指针,返回时 v0 指向这个对应的结构,这些都是由编译器自动完成。
a0-a3. 用来传递函数入参给子函数。看一下这个例子:
ret = strncmp("bear","bearer",4)参数少于 16 字节,可以放入寄存器中,在 strncmp 的函数里,a0 存放的是 "bear" 这个字符串所在的只读区地址,a1 是 "bearer" 的地址,a2 是 4.t0-t9 临时寄存器 s0-s8 保留寄存器 这两种寄存器需要放在一起说,它们是 mips 汇编里面代码里见到的最多的两种寄存器,它们的作用都是存取数据,做计算、移位、比较、加载、存储等等,区别在于,t0-t9 在子程序中可以使用其中的值,并不必存储它们,它们很适合用来存放计算表达式时使用的“临时”变量。如果这些变量的使用要要跳转到子函数之前完成,因为子函数里很可能会使用相同的寄存器,而且不会有任何保护。如果子程序里不会调用其它函数那么建议尽量多的使用t0-t9,这样可以避免函数入口处的保存和结束时的恢复。 相反的,s0-s8 在子程序的执行过程中,需要将它们存储在堆栈里,并在子程序结束前恢复。从而在调用函数看来这些寄存器的值没有变化。
k0, k1. 这两个寄存器是专门预留给异常处理流程中使用。异常处理流程中有什么特别的地方吗?当然。当 MIPS CPU 在任务里运行的时候,一旦有外部中断或者异常发生,CPU 就会立刻跳转到一个固定地址的异常 handler 函数执行,并同时将异常结束后返回到任务的指令地址记录在 EPC 寄存器(Exception Program Counter)里。习惯性的,异常 handler 函数开头总是会保持现场即 MIPS 寄存器到中断栈空间里,而在异常返回前,再把这些寄存器的值恢复回去。那就存在一个问题,这个 EPC 里的值存放在哪里?异常 handler 函数的最后肯定是一句
jr x,X 是一个 MIPS 寄存器,如果存放在前面提到的 t0,s0 等等,那么 PC 跳回任务执行现场时,这个寄存器里的值就不再是异常发生之前的值。所以必须要有时就可以一句jr k0指令返回了。 k1 是另外一个专为异常而生的寄存器,它可以用来记录中断嵌套的深度。CPU 在执行任务空间的代码时,k1 就可以置为 0,进入到中断空间,每进入一次就加 1,退出一次相应减 1,这样就可以记录中断嵌套的深度。这个深度在调试问题的时候经常会用到,同时应用程序在做一次事情的时候可能会需要知道当前是在任务还是中断上下文,这时,也可以通过 k1 寄存器是否为 0 来判断。sp 指向当前正在操作的堆栈顶部,它指向堆栈中的下一个可写入的单元,如果从栈顶获取一个字节是 sp-1 地址的内容。在有 RTOS 的系统里,每个 task 都有自己的一个堆栈空间和实时 sp 副本,中断也有自己的堆栈空间和 sp 副本,它们会在上下文切换的过程中进行保存和恢复。
gp 这是一个辅助型的寄存器,其含义较为模糊,MIPS 官方为该寄存器提供了两个用法建议,一种是指向 Linux 应用中位置无关代码之外的数据引用的全局偏移量表; 在运行 RTOS 的小型嵌入式系统中,它可以指向一块访问较为频繁的全局数据区域,由于MIPS 汇编指令长度都是 32bit,指令内部的 offset 为 16bit,且为有符号数,所以能用一条指令以 gp 为基地址访问正负 15bit 的地址空间,提高效率。那么编译器怎么知道gp初始化的值呢?只要在 link 文件中添加 _gp 符号,连接器就会认为这是 gp 的值。我们在上电时,将 _gp 的值赋给 gp 寄存器就行了。 话说回来,这都是 MIPS 设计者的建议,不是强制,楼主还见过一种 gp 寄存器的用法,来在中断和任务切换时做 sp 的存储过渡,也是可以的。
fp 这个寄存器不同的编译器对其解释不同,GNU MIPS C 编译器使用其作为帧指针,指向堆栈里的过程帧(一个子函数)的第一个字,子函数可以用其做一个偏移访问栈帧里的局部变量,sp 也可以较为灵活的移动,因为在函数退出之前使用 fp 来恢复;还要一种而 SGI 的 C 编译器会将这个寄存器直接作为 s8,扩展了一个保留寄存器给编译器使用。
ra 在函数调用过程中,保持子函数返回后的指令地址。汇编语句里函数调用的形式为:
jal function_X这条指令 jal(jump-and-link,跳转并链接) 指令会将当期执行运行指令的地址 +4 存储到 ra 寄存器里,然后跳转到 function_X 的地址处。相应的,子函数返回时,最常见的一条指令就是jr rara 是一个对于调试很有用的寄存器,系统的运行的任何时刻都可以查看它的值以获取 CPU 的运行轨迹。
最后,如果纯写汇编语句的话,这些寄存器当中除了 zero 之外,其它的基本上都可以做普通寄存器存取数据使用(这也是它们为什么会定义为“通用寄存器”,而不像其它的协处理器、或者外设的都是专用寄存器,其在出厂时所有的功能都是定死的),那为什么有这么多规则呢 ?MIPS 开发者们为了让自己的处理器可以运行像 C、Java 这样的高级语言,以及让汇编语言和高级语言可以安全的混合编程而设计的一套 ABI(应用编程接口),不同的编译器的设计者们就会有据可依,系统程序员们在阅读、修改汇编程序的时候也能根据这些约定而更为顺畅地理解汇编代码的含义。
程序结构
本质上只是带有数据声明的纯文本文件,程序代码 ( 文件名应以后缀 .s 结尾,或者.asm )
数据声明部分后跟程序代码部分
数据声明
数据以
.data为标识声明变量后,即在内存中分配空间
代码
放在用汇编指令
.text标识的文本部分中包含程序代码( 指令 )
给定标签
main代码执行的起点 ( 和 C 语言一样 )程序结束标志(见下面的系统调用)
注释
- # 表示单行注释
# 后面的任何内容都会被视为注释
- MIPS 汇编语言程序的模板:
#给出程序名称和功能描述的注释
#Template.s
#MIPS汇编语言程序的Bare-bones概述
.data #变量声明遵循这一行
#...
.text#指令跟随这一行
main:#表示代码的开始(执行的第一条指令)
#...
#程序结束,之后留空,让SPIM满意.
变量声明
声明格式:
name:storage_type value(s)
使用给定名称和指定值为指定类型的变量创建空间
value (s) 通常给出初始值; 对于.space,给出要分配的空格数
注意:标签后面跟冒号(:)
- 例如
var1:.word 3 #创建一个初始值为 3 的整数变量
array1:.byte'a','b' #创建一个元素初始化的 2 元素字符数组到 a 和 b
array2:.space 40 #分配 40 个连续字节, 未初始化的空间可以用作 40 个元素的字符数组, 或者是
#10 个元素的整数数组.
读取/写入 ( Load/Store )指令
- 对 RAM 的访问, 仅允许使用加载和存储指令 ( 即
load或者store) - 所有其他指令都使用寄存器参数
load:
lw register_destination,RAM_source
#将源内存地址的字 ( 4 个字节 ) 复制到目标寄存器,(lw中的'w'意为'word',即该数据大小为4个字节)
lb register_destination,RAM_source
#将源内存地址的字节复制到目标寄存器的低位字节, 并将符号映射到高位字节 ( 同上, lb 意为 load byte )
store:
sw register_source,RAM_destination
#将源寄存器的字存储到目标内存RAM中
sb register_source,RAM_destination
#将源寄存器中的低位字节存储到目标内存RAM中
立即加载:
li register_destination,value
#把立即值加载到目标寄存器中,顾名思义, 这里的 li 意为 load immediate, 即立即加载.
- 例子
.data
var1: .word 23 # 给变量 var1 在内存中开辟空间, 变量初始值为 23
.text
__start:
lw $t0, var1 # 将内存单元中的内容加载到寄存器中 $t0: $t0 = var1
li $t1, 5 # $t1 = 5 ("立即加载")
sw $t1, var1 # 把寄存器$t1的内容存到内存中 : var1 = $t1
done
间接和立即寻址
仅用于读取和写入指令
直接给地址:
la $t0,var1
将 var1 的内存地址(可能是程序中定义的标签)复制到寄存器
$t0中间接寻址, 地址是寄存器的内容, 类似指针:
lw $t2,($t0)
- 将
$t0中包含的 RAM 地址加载到$t2
sw $t2,($t0)
将
$t2寄存器中的字存储到$t0中包含的地址的 RAM 中基于偏移量的寻址:
lw $t2, 4($t0)
- 将内存地址 (
$t0 + 4) 的字加载到寄存器$t2中 - “ 4 ” 给出了寄存器
$t0中地址的偏移量
sw $t2,-12($t0)
- 将寄存器
$t2中的字放到内存地址($t0 - 12) 负偏移也是可以的, 反向漂移方不方 ?
注意:基于偏移量 的寻址特别适用于:
数组; 访问元素作为与基址的偏移量
栈; 易于访问偏离栈指针或帧指针的元素
例子
.data
array1: .space 12 # 定义一个 12字节 长度的数组 array1, 容纳 3个整型
.text
__start: la $t0, array1 # 让 $t0 = 数组首地址
li $t1, 5 # $t1 = 5 ("load immediate")
sw $t1, ($t0) # 数组第一个元素设置为 5; 用的间接寻址; array[0] = $1 = 5
li $t1, 13 # $t1 = 13
sw $t1, 4($t0) # 数组第二个元素设置为 13; array[1] = $1 = 13
#该数组中每个元素地址相距长度就是自身数据类型长度,即4字节, 所以对于array+4就是array[1]
li $t1, -7 # $t1 = -7
sw $t1, 8($t0) # 第三个元素设置为 -7;
#array+8 = (address[array[0])+4)+ 4 = address(array[1]) + 4 = address(array[2])
done
算术指令
- 最多使用3个参数
- 所有操作数都是寄存器; 不能有内存地址的存在
- 操作数大小是字 ( 4个字节 ), 32位 = 4 * 8 bit = 4bytes = 1 word
add $t0,$t1,$t2 # $t0 = $t1 + $t2;添加为带符号(2 的补码)整数
sub $t2,$t3,$t4 # $t2 = $t3 Ð $t4
addi $t2,$t3, 5 # $t2 = $t3 + 5;
addu $t1,$t6,$t7 # $t1 = $t6 + $t7;跟无符号数那样相加
subu $t1,$t6,$t7 # $t1 = $t6 - $t7;跟无符号数那样相减
mult $t3,$t4 # 运算结果存储在hi,lo(hi高位数据, lo地位数据)
div $t5,$t6 # Lo = $t5 / $t6 (整数商)
# Hi = $t5 mod $t6 (求余数)
#商数存放在 lo, 余数存放在 hi
mfhi $t0 # 把特殊寄存器 Hi 的值移动到 $t0 : $t0 = Hi
mflo $t1 # 把特殊寄存器 Lo 的值移动到 $t1: $t1 = Lo
#不能直接获取 hi 或 lo中的值, 需要mfhi, mflo指令传值给寄存器
move $t2,$t3 # $t2 = $t3
流程控制
分支 ( if-else )
- 条件分支的比较内置于指令中
b target #无条件分支,直接到程序标签目标
beq $t0, $t1, target #if $t0 = $ t1, 就跳到目标
blt $t0, $t1, target #if $t0 <$ t1, 就跳到目标
ble $t0, $t1, target #if $t0 <= $ t1, 就跳到目标
bgt $t0, $t1, target #if $t0 $ t1, 就跳到目标
bge $t0, $t1, target #if $t0 = $ t1, 就跳到目标
bne $t0, $t1, target #if $t0 < $t1, 就跳到目标
跳转 ( while, for, goto )
j target #看到就跳, 不用考虑任何条件
jr $t3 #类似相对寻址,跳到该寄存器给出的地址处
子程序调用
子程序调用:“ 跳转和链接 ” 指令
jal sub_label #“跳转和链接”
- 将当前的程序计数器保存到
$ra中 跳转到
sub_label的程序语句子程序返回:“跳转寄存器”指令
jr $ra #“跳转寄存器”
跳转到$ ra中的地址(由jal指令存储)
注意:寄存地址存储在寄存器
$ra中; 如果子例程将调用其他子例程,或者是递归的,则返回地址应该从$ra复制到栈以保留它,因为jal总是将返回地址放在该寄存器中,因此将覆盖之前的值
系统调用和 I / O( 针对 SPIM 模拟器 )
- 通过系统调用实现从输入/输出窗口读取或打印值或字符串,并指示程序结束
syscall- 首先在寄存器
$v0和$a0 - $a1中提供适当的值 寄存器
$v0中存储返回的结果值( 如果有的话 )下表列出了可能的 系统调用 服务。
| Service 服务 | Code in $v0 对应功能的调用码 |
Arguments 所需参数 | Results 返回值 |
|---|---|---|---|
| print 一个整型数 | $v0 = 1 |
$a0 = 要打印的整型数 |
|
| print 一个浮点数 | $v0 = 2 |
$f12 = 要打印的浮点数 |
|
| print 双精度数 | $v0 = 3 |
$f12 = 要打印的双精度数 |
|
| print 字符串 | $v0 = 4 |
$a0 = 要打印的字符串的地址 |
|
| 读取 ( read ) 整型数 | $v0 = 5 |
$v0 = 读取的整型数 |
|
| 读取 ( read ) 浮点数 | $v0 = 6 |
$v0 = 读取的浮点数 |
|
| 读取 ( read ) 双精度数 | $v0= 7 |
$v0 = 读取的双精度 |
|
| 读取 ( read ) 字符串 | $v0 = 8 |
将读取的字符串地址赋值给 $a0; 将读取的字符串长度赋值给 $a1 |
|
这个应该和 C 语言的 sbrk() 函数一样 |
$v0 = 9 |
需要分配的空间大小(单位目测是字节 bytes) | 将分配好的空间首地址给 $v0 |
| exit | $v0 =10 |
这个还要说吗.....= _ = |
print_string即print 字符串服务期望启动以 null 结尾的字符串。指令.asciiz创建一个以 null 结尾的字符串。
read_int,read_float和read_double服务读取整行输入,包括换行符\n。read_string服务与 UNIX 库例程 fgets 具有相同的语义。- 它将最多 n-1 个字符读入缓冲区,并以空字符终止字符串。
- 如果当前行中少于 n-1 个字符,则它会读取并包含换行符,并使用空字符终止该字符串。
- 就是输入过长就截取,过短就这样,最后都要加一个终止符。
sbrk服务将地址返回到包含 n 个附加字节的内存块。这将用于动态内存分配。- 退出服务使程序停止运行
例子 : 打印一个存储在 $2 的整型数
li $v0, 1 #声明需要调用的操作代码为 1 ( print_int ), 然后赋值给 $v0
move $a0, $t2 #把这个要打印的整型数赋值给 $a0
syscall #让操作系统执行我们的操作
例子 : 读取一个数,并且存储到内存中的 int_value 变量中
li $v0, 5 #声明需要调用的操作代码为 5 ( read_int ), 然后赋值给 $v0 syscall #让操作系统执行我们的操作, 然后 $v0 = 5 sw $v0, int_value #通过写入(store_word)指令 将 $v0 的值(5)存入内存中例子 : 打印一个字符串 ( 这是完整的,其实上面例子都可以直接替换 main: 部分,都能直接运行 )
.data
string1 .asciiz "Print this.\n" # 字符串变量声明
# .asciiz 指令使字符串 null 终止
.text
main: li $v0, 4 # 将适当的系统调用代码加载到寄存器 $v0 中
# 打印字符串, 赋值对应的操作代码 $v0 = 4
la $a0, string1 # 将要打印的字符串地址赋值 $a0 = address(string1)
syscall # 让操作系统执行打印操作
要指示程序结束, 应该退出系统调用, 所以最后一行代码应该是这个 :
li $v0, 10 #对着上面的表, 不用说了吧
syscall # 让操作系统结束这一切吧 !
补充 : MIPS 指令格式
- R格式
| 6 | 5 | 5 | 5 | 5 | 6 |
|---|---|---|---|---|---|
| op | rs | rt | rd | shamt | funct |
用处: 寄存器 - 寄存器 ALU 操作 读写专用寄存器
- I格式
| 6 | 5 | 5 | 16 |
|---|---|---|---|
| op | rs | rt | 立即数操作 |
用处: 加载/存储 字节,半字,字,双字 条件分支,跳转,跳转并链接寄存器
- J格式
| 6 | 26 |
|---|---|
| op | 跳转地址 |
用处: 跳转,跳转并链接 陷阱和从异常中返回
各字段含义: op : 指令基本操作,称为操作码。 rs : 第一个源操作数寄存器。 rt : 第二个源操作数寄存器。 rd : 存放操作结果的目的操作数。 shamt : 位移量; funct : 函数,这个字段选择 op 操作的某个特定变体。
例:
add $t0,$s0,$s1
表示$t0=$s0+$s1,即 16 号寄存器( s0 ) 的内容和 17 号寄存器 ( s1 ) 的内容相加,结果放到 8 号寄存器 ( t0 )。
指令各字段的十进制表示为:
| 0 | 16 | 17 | 8 | 0 | 32 |
|---|---|---|---|---|---|
op = 0 和 funct = 32 表示这是加法,
16 = $s0 表示第一个源操作数 ( rs ) 在 16 号寄存器里,
17 = $s1 表示第二个源操作数 ( rt ) 在 17 号寄存器里,
8 = $t0 表示目的操作数 ( rd ) 在 8 号寄存器里。
把各字段写成二进制,为:
| 000000 | 10000 | 10001 | 01000 | 00000 | 100000 |
|---|---|---|---|---|---|
这就是上述指令的机器码( machine code ), 可以看出是很有规则性的。
补充 : MIPS 常用指令集
lb/lh/lw : 从存储器中读取一个 byte / half word / word 的数据到寄存器中.
如lb $1, 0($2)
sb/sh/sw : 把一个 byte / half word / word 的数据从寄存器存储到存储器中.
如 sb $1, 0($2)
add/addu : 把两个定点寄存器的内容相加
add $1,$2,$3($1=$2+$3); u 为不带符号加
addi/addiu : 把一个寄存器的内容加上一个立即数
add $1,$2,#3($1=$2+3); u 为不带符号加
sub/subu :把两个定点寄存器的内容相减
div/divu : 两个定点寄存器的内容相除
mul/mulu : 两个定点寄存器的内容相乘
and/andi : 与运算,两个寄存器中的内容相与
and $1,$2,$3($1=$2 & $3);i为立即数。
or/ori : 或运算。
xor/xori : 异或运算。
beq/beqz/benz/bne : 条件转移 eq 相等,z 零,ne 不等
j/jr/jal/jalr : j 直接跳转;jr 使用寄存器跳转
lui : 把一个 16 位的立即数填入到寄存器的高 16 位,低 16 位补零
sll/srl : 逻辑 左移 / 右移
sll $1,$2,#2
slt/slti/sltui : 如果 $2 的值小于 $3,那么设置 $1 的值为 1,否则设置 $1 的值为 0
slt $1,$2,$3
mov/movz/movn : 复制,n 为负,z 为零
mov $1,$2; movz $1,$2,$3 ( $3 为零则复制 $2 到 $1 )
trap : 根据地址向量转入管态
eret : 从异常中返回到用户态